Краткое введение в концепции машинного обучения на Python

Машинное обучение - это ветвь искусственного интеллекта, которая занимается изучением вычислительных алгоритмов и статистических моделей для выполнения задач с помощью шаблонов и интерференции вместо явных задач. Машина (ваш компьютер) принимает данные и алгоритм, учится на них, а затем может использовать их для прогнозирования других новых экземпляров. Машинное обучение - это набор инструментов, используемых для построения моделей на основе данных, которые могут помочь предсказать новые типы одних и тех же данных. Модели машинного обучения сейчас очень популярны во всем мире. Вы, должно быть, когда-то задавались вопросом, как Facebook узнал, что вы кого-то знаете, или как Spotify рекомендовал вам этот действительно крутой джем. Что ж, это машинное обучение, и точно так же, как Facebook может привлечь кого-то, кого вы не знаете, основано на том факте, что модели машинного обучения не всегда точны на 100%.
Машинное обучение состоит из контролируемого обучения, когда мы знаем цель или прошлый ответ, и неконтролируемого обучения, когда целей нет.
В этой статье мы рассмотрим основы машинного обучения, рассмотрев основные способы выполнения операций моделями машинного обучения, чтобы дать нам интересную обратную связь. Эта статья посвящена обучению под наблюдением, так как это введение.
Приведенные ниже концепции охватывают основы машинного обучения.
Группировка данных по характеристикам и целям
Как подчеркивалось ранее, при контролируемом обучении мы стремимся прогнозировать значения на основе прошлых данных (цели), следовательно; набор данных, с которым мы работаем, имеет столбец, содержащий значения, которые мы пытаемся предсказать. Это целевой столбец. В то время как другие столбцы, которые будут использоваться для прогнозирования цели, называются функциями. Наборы данных могут быть неоднозначными, содержать бесполезные данные, от которых мы хотели бы избавиться, и здесь нам пригодятся анализ и обработка данных. Мы также хотели бы иметь хорошее знание функций, и мы можем сделать это, обладая хорошими знаниями исследовательского анализа данных.
Основные операции алгоритма машинного обучения
Классификация: при классификации модели машинного обучения группируют данные в разные части на основе предоставленного алгоритма. Популярные алгоритмы классификации, среди прочего, включают в себя K Ближайших Соседей, Машины Опорных Векторов и с помощью концепции, называемой перекрестной проверкой; мы сможем выбрать лучший из них для работы с нашими данными.
Регрессия: алгоритмы регрессии работают, выявляя взаимосвязь между двумя или более функциями в нашей модели. Примерами являются алгоритмы линейной и логистической регрессии.
Регрессия и классификация относятся к одной и той же категории контролируемого машинного обучения. Основное различие между ними заключается в том, что выходная переменная в регрессии является числовой (или непрерывной), в то время как для классификации является категориальной (или дискретной).
Рабочий процесс машинного обучения
Импорт: импортируя, мы получаем необходимые инструменты, которые собираемся использовать в нашей модели машинного обучения. Примеры: алгоритмы и инструменты, которые мы используем для исследовательского анализа данных.
from sklearn.linearmodel import LinearRegression
Инстанцирование: это процесс создания экземпляра метода машинного обучения. В то время как некоторые из них принимают параметры, такие как K Ближайших Соседей, другие не принимают параметры.
my_model = LinearRegression()
Разделение на данные для обучения и тестирования: мы разделяем данные на наборы для обучения и тестирования. Мы продолжаем работать с обучающим набором, а затем сравниваем их с тестовым набором, чтобы увидеть, насколько хорошо работает наша модель.
from sklearn.model_selection import train_test_split
X = feature columns
y = target column
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=* train_test_split * выполняет распаковку кортежей данных. Аргумент «test_size», показанный выше, - это часть данных, которую мы готовы выделить методу машинного обучения для обучения.
Подбор: подбирая модель, мы передаем обучающий набор наших данных алгоритму для работы. Мы могли настроить алгоритм работы с подобранными данными. Мы бы подобрали данные обучения к методу машинного обучения.
my_model.fit(X_train, y_train)
Прогнозирование: цель использования алгоритма машинного обучения состоит в том, чтобы иметь возможность получать на его основе прогнозы и обратную связь, и мы делаем это, используя метод прогнозирования алгоритма машинного обучения. Большинство алгоритмов машинного обучения уже сложны и готовы к использованию, поэтому большая часть работы специалиста по данным заключается в уточнении данных для алгоритма. Мы прогнозируем X_test из распаковки кортежа train_test_split.
prediction = my_model.predict(X_test)

ОЦЕНКА РАБОТЫ МОДЕЛИ
Отчет о классификации: отчет о классификации - это показатель, который дает таблицу того, насколько хорошо алгоритм выполняется в процентах. В таблице указаны точность, отзыв и результат f1. Столбец точности показывает нам процентную оценку того, насколько хорошо алгоритм классифицировал нашу модель. Столбец отзыва дает нам обратную связь о том, как алгоритм классифицировал данные, которые не принадлежали к категории, в то время как оценка f1 представляет собой гармоническое среднее значение точности и отзыва. Отчет о классификации пригодится для оценки модели, так как его легко получить.
from sklearn.metrics import classification_report
print(classification_report(y_test,predictions))

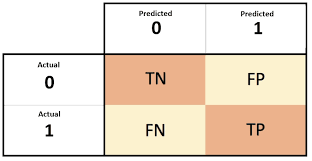
Матрица ошибок: метод матрицы ошибок используется для обобщения того, как алгоритм работал с нашими данными. В матрице ошибок строки соответствуют значениям, предсказанным алгоритмом, а столбцы соответствуют известным истинам (фактическим). Значения на диагонали указывают, где алгоритм правильно классифицировал наши данные, а другие показывают, где алгоритм дал сбой. Используя матрицу ошибок, мы можем сравнить, насколько хорошо разные алгоритмы работают с нашими данными, а затем выбрать алгоритм, который лучше всего подходит для наших данных.
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test,predictions))
Перекрестная проверка: перекрестная проверка позволяет нам сравнивать различные методы машинного обучения и понимать, насколько хорошо они будут работать на практике, что помогает нам выбрать алгоритм машинного обучения, который лучше всего подходит для наших данных. Перекрестная проверка делает это путем разделения данных на наборы для обучения и тестирования. Разделение данных на n числа, тип перекрестной проверки - это n перекрестная проверка, поскольку количество разделений является произвольным. Перекрестная проверка использует каждую часть разделенных данных для доставки.
Смещение и отклонение: смещение - это неспособность метода машинного обучения уловить истинную взаимосвязь между функциями. Отклонение - это разница в подгонках между разными наборами данных. В машинном обучении хороший алгоритм - это алгоритм с низким смещением, который может точно моделировать истинные отношения и имеет низкую изменчивость (он должен обеспечивать стабильно хорошие прогнозы для разных наборов данных). Когда есть случай высокого смещения и низкого отклонения, модель недостаточно подогнана, а когда есть низкое смещение и высокое отклонение, модель переоборудована. Обмен смещения на отклонение и наоборот - это компромисс смещения отклонения.

Зная эти базовые концепции, освоить другие методы машинного обучения будет довольно легко.