Как научиться машинному обучению — Советы и ресурсы для практического изучения ML
В наши дни многие люди хотят изучать машинное обучение. Но устрашающая программа обучения по восходящей схеме, которую предлагают большинство преподавателей машинного обучения, уже отпугивает многих новичков.
В этом уроке я переворачиваю учебный план с ног на голову и обрисовываю, что я считаю самым быстрым и простым способом получить твердое представление о машинном обучении.
Оглавление
Учебная программа, которую я предлагаю, представляет собой повторяющийся многоэтапный процесс, который выглядит следующим образом:
- Шаг 0: погрузитесь в сферу машинного обучения
- Шаг 1. изучите один проект, который похож на ваш конечный результат
- Шаг 2. изучите язык программирования
- Шаг 3. изучите библиотеки сверху вниз
- Шаг 4. сделайте один проект, которым вы увлечены, максимум за один месяц.
- Шаг 5. определите один пробел в своих знаниях и узнайте о нем
- Шаг 6: повторите шаги с 0 по 5.
Это циклический план обучения, потому что 6-й шаг - это переход к шагу 0!
Как отказ от ответственности, эта учебная программа может показаться вам странной. Но я испытал это в боевых условиях, когда преподавал машинное обучение студентам Университета Макгилла.
Я перепробовал множество итераций этой учебной программы, начиная с теоретически превосходящего подхода "снизу вверх". Но, исходя из опыта, этот прагматичный подход сверху вниз дает наилучшие результаты.
Одна распространенная критика, которую я слышу, заключается в том, что люди, не начинающие с основ, таких как статистика или линейная алгебра, будут плохо разбираться в машинном обучении и не будут знать, что они делают при моделировании.
Теоретически, да, это правда, и именно поэтому я начал преподавать ML с подходом "снизу вверх". На практике этого никогда не было.
На самом деле произошло то, что, поскольку студенты знали, как проводить моделирование высокого уровня, они были гораздо более склонны вникать в вещи низкого уровня самостоятельно, поскольку они видели прямую пользу, которую это принесет их навыкам более высокого уровня.
Этого контекста, который они смогли установить для себя, не было бы, если бы они начали с самого низа — и именно здесь, я считаю, большинство учителей теряют своих учеников.
С учетом всего сказанного, давайте перейдем к реальному плану обучения! 🚀🚀🚀
Шаг 0: погрузитесь в сферу машинного обучения
Самая первая часть изучения чего-либо - это потратить некоторое время, чтобы понять, где все заканчивается и в чем заключается ваш интерес.
Это будет иметь два основных преимущества:
- Знание размера поля позволит вам понять, что вы ничего не упускаете, поэтому это повысит вашу сосредоточенность.
- Будет легче нарисовать путь в своей ментальной модели, если вы будете знать, как выглядит пейзаж, по которому вы прогуливаетесь.

Чтобы должным образом погрузиться в эту область и отточить свой план обучения, вы должны ответить на эти три вопроса по порядку:
- Что можно делать с машинным обучением?
- Что вы хотите делать с машинным обучением?
- Как вы это делаете?
Эти вопросы позволят вам сосредоточиться на чем-то очень конкретном и доступном для изучения, а также позволят вам увидеть более широкую картину.
Давайте рассмотрим каждый из этих вопросов более подробно.
Что можно делать с машинным обучением?
Это очень широкий вопрос, который будет меняться от месяца к месяцу. Самое замечательное в этой учебной программе состоит в том, что на каждом этапе прохождения вы будете тратить некоторое время на изучение того, что возможно в этой области.
Это позволит вам усовершенствовать вашу ментальную модель машинного обучения. Так что, если у вас нет стопроцентно точного представления о том, что возможно, при первом проходе, это не имеет большого значения. Приблизительное понимание лучше, чем ничего.

Вот краткий обзор того, что вы можете делать с машинным обучением, от технических до практических приложений.
Темы технического машинного обучения
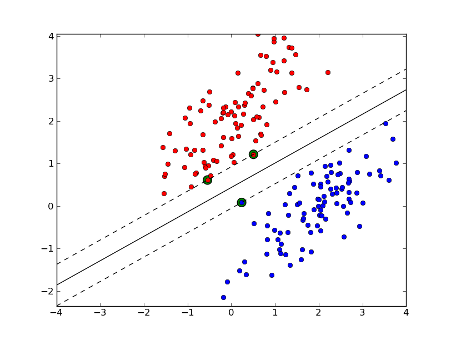
- Контролируемое обучение: Этот тип обучения включает в себя ввод и маркировку выходных данных модели для ее обучения. Как только тренинг будет завершен, вы должны технически быть в состоянии ввести его, и он выдаст правильный результат.
- Неконтролируемое обучение: это обучение включает ввод без вывода. Вы просите модель разобраться в закономерностях в данных.
- Обучение с подкреплением: Эта настройка ML включает агента, среду, действия, которые может выполнять агент, и вознаграждения. Это похоже на то, как вы дрессировали бы собаку с помощью лакомств.
- Онлайн-обучение: этот тип обучения может быть как контролируемым, так и неконтролируемым. Особенность заключается в том, что модель может обновляться «в режиме онлайн» по мере поступления потока данных.
- Трансферное обучение: этот тип обучения - это когда вы используете уже обученную модель в качестве отправной точки для другой учебной задачи. Это значительно ускоряет изучение второго задания.
- Коллективное обучение: Этот метод ML включает в себя объединение нескольких обученных предикторов (один за другим или путем голосования результатов) и использование этого коллектива предикторов в качестве окончательного предиктора.
Есть еще много разновидностей машинного обучения, но это хорошая отправная точка.
Распространенные модели машинного обучения

- Линейная регрессия: это старая добрая формула
y = ax + b - Логистическая регрессия: это тип модели, моделирующей вероятность класса или нескольких классов. Несмотря на то, что в названии есть регресс, это модель классификации.
- Дерево решений: модель дерева решений создает дерево «решений» или формул, следование которым приводит к желаемому результату. Эти типы моделей важны, потому что их легко понять и проверить после обучения.
- Машина опорных векторов (SVM): Думайте об этой модели как о построении плоскости, разделяющей два класса с максимальной шириной между ними. Это немного сложнее, но представьте линию с толщиной, и вы на полпути.
- Наивный Байесовский: эти типы классификаторов используют теорему Байеса, которая предполагает, что все функции независимы друг от друга. Однако это случается редко, поэтому это называется наивным. На практике это работает на удивление хорошо, даже когда это предположение не выполняется.
- k-ближайшие соседи: этот тип классификатора не требует обучения, он просто запоминает все элементы в наборе данных. Затем он может дать вам результат, основанный на расстоянии входа от другой точки в наборе данных.
- K-Means: эта неконтролируемая модель, учитывая количество кластеров, выясняет, какие точки принадлежат какому кластеру. Она будет делать это путем многократного изменения центроида каждого кластера, пока он не сойдется к чему-то стабильному.
- Random Forest: Это метод коллектива, который использует множество очень простых классификаторов дерева решений. Выходные данные модели - это выходные данные класса по большинству деревьев решений.
- Алгоритмы уменьшения размерности: существует множество алгоритмов уменьшения размерности, одним из которых является анализ основных компонентов. Суть всех этих алгоритмов заключается в том, что они могут создать отображение из набора данных с большим количеством измерений (функций) в представление с меньшим количеством. Когда он сопоставляется с 2 или 3 измерениями, он позволяет нам визуализировать набор данных высокой размерности в 2D или 3D
- XGBoost: Эта модель представляет собой регуляризованную модель с усилением градиента. В двух словах, в нем есть неэффективные слушатели, настроенные последовательно, а не параллельно (например, Random Forest). Это очень хорошая модель, и обычно она является лучшей на соревнованиях по машинному обучению.
- Глубокая нейронная сеть: эти типы моделей представляют собой отдельную область. В основном это неэффективные предикторы, поставленные как последовательно, так и параллельно. Эти модели могут создавать иерархическое представление данных, которое дает отличные результаты. Они общеизвестно привередливы (мягко говоря) к тренировкам из-за своей большой способности. Для этих моделей возможно множество архитектур, например CNN и трансформаторы.
Существует множество моделей машинного обучения. Но, к счастью, вам не нужно знать их все, чтобы хорошо разбираться в машинном обучении.
На самом деле, если вы знаете линейную регрессию, SVM, XGBoost и некоторые формы глубокой нейронной сети, вы можете справиться с большинством проблем. Но изучение того, как обучается модель, дает вам больше умственной гибкости и позволяет по-другому думать о проблемах.
Распространенные приложения машинного обучения
Это одна из областей, где все будет кардинально меняться от месяца к месяцу. Практически в любой области, где у вас собираются данные, вы можете добавить ML в микс.

Дело в том, что широта и глубина применения машинного обучения постоянно расширяются. Так что не слишком расстраивайтесь, если думаете, что имеете лишь поверхностное понимание того, что возможно.
- Компьютерное зрение: машинное обучение (и, в частности, глубокое обучение) в настоящее время находится на той стадии, когда оно довольно хорошо справляются со всем, что связано с изображениями и распознаванием объектов. Существуют также генеративные виды анализа, которые вы можете выполнять, когда нейронная сеть может генерировать изображение, используя определенные архитектурные приемы (например, GAN или Neural Style Transfer).
- Обработка естественного языка (NLP): включает в себя довольно много подтем, таких как ответы на вопросы, перевод, классификация документов или создание текста.
- Медицинский диагноз: когда вы имеете дело с медицинскими изображениями, довольно часто для их анализа используются методы компьютерного зрения. Но медицинский диагноз также может включать показания, не основанные на изображениях, такие как концентрация определенного гормона в образце крови.
- Биоинформатика: это очень широкая область, пересекающаяся со многими другими методами. В целом биоинформатика использует методы машинного обучения для работы с биоданными и их анализа. Здесь вы можете рассматривать сворачивание белков как одну из задач биоинформатики, которая в значительной степени полагается на машинное обучение.
- Обнаружение выбросов. Распознавание того, что что-то является частью категории или когда оно настолько далеко от основной массы данных, что должно быть выбросом, является очень важным упражнением во многих областях.
- Прогнозирование погоды: все, что действительно связано с огромным количеством точек данных с течением времени, будет хорошим кандидатом для применения машинного обучения. Прогнозирование погоды - это один из видов проблем, для решения которых доступно множество данных за все время.
Этот список можно продолжать какое-то время. Дело здесь в том, чтобы составить хорошую карту того, что возможно, чтобы вы чувствовали себя уверенно на следующем этапе вашего учебного путешествия.
Что вы хотите делать с машинным обучением?
Этот вопрос является самым важным. Вы не сможете осмысленно делать все в машинном обучении (или любой другой области). Вы должны быть очень разборчивы в том, что, по вашему мнению, является хорошим использованием вашего времени, а что нет.
Один из способов сделать этот выбор - расположить свои интересы в порядке убывания.

Затем просто выберите свой самый интересный и прикрепите его туда, где вы можете его увидеть. Это то, что вы будете изучать, и ничего больше, пока ваш рейтинг не изменится.
И имейте в виду, что вы определенно можете изменить свои интересы. Если вас очень интересует конкретная тема, но после того, как вы узнали о ней больше, она перестала быть такой интересной, тогда можно отказаться от этой темы и заняться другой. Вот и вся причина, по которой вы делаете этот первый шаг планирования.
Здесь, если вас интересует много предметов, я настоятельно рекомендую вам посвятить цикл только одному. Все предметы так или иначе взаимосвязаны. Если углубиться в тему, вы сможете увидеть эти связи. Перепрыгивать поверхностно от темы к теме не нужно.
Если бы я узнал что-то новое прямо сейчас во время своего сотого прохождения по этой учебной программе, я бы погрузился в нейронные сети Graph и их применение в управлении цепочкой поставок.
Как вы это делаете?
Теперь, когда вы знаете, что вас интересует и где это находится в общем контексте, потратьте некоторое время на то, чтобы понять, как люди это делают.

Очень важно уделять время пониманию того, что вы будете проводить недели (или дольше), изучая. Возможность получить контекст, чтобы обосновать то, что вы будете изучать, и знание того, о чем вам не нужно знать, сэкономит вам много времени и энергии.
Это также поможет вам понять, на чем вам действительно не нужно сосредотачивать свою энергию. Например, если вы обнаружите, что большинство людей не используют HTML, CSS и JavaScript в своей повседневной работе по машинному обучению, не сосредотачивайтесь на этих технологиях.
Что касается того, что люди используют в ML, существует широкий спектр языков программирования и инструментов в зависимости от приложения. У вас есть инструменты на C ++, Java, Lua, Swift, JavaScript, Python, R, Julia, MATLAB, Rust… и этот список можно продолжать и продолжать.
Но большинство практиков сосредоточено вокруг Python и его экосистемы пакетов. Python - относительно простой для понимания язык программирования с процветающей экосистемой. Это означает, что люди, которые хотят создавать инструменты машинного обучения, с большей вероятностью будут разрабатывать эти инструменты с интерфейсом Python.
Фактические инструменты обычно не разрабатываются на чистом Python, потому что язык довольно медленный. Но поскольку у них есть прямой интерфейс с Python, пользователь не узнает, что это на самом деле библиотека C ++, завернутая в Python.
Если вы не поняли последнюю часть, все в порядке. Просто имейте в виду, что библиотеки Python + в Python - очень безопасный вариант для изучения.
Инструменты для машинного обучения
Обычно инструменты для обучения машинному обучению предпологают следующие:
- Python для программирования высокого уровня
- Pandas для манипулирования наборами данных
- Numpy для численных вычислений на процессоре
- Scikit-learn для моделей машинного обучения без глубокого обучения
- Tensorflow или Pytorch для моделей машинного обучения с глубоким обучением
- Более высокий уровень обертки библиотеки Deep Learning, как Keras и fast.ai
- Основы Git для работы над вашим проектом
- Блокнот Jupyter или Google Colab для экспериментов с кодом
Есть еще много инструментов, которые вы можете использовать! Будьте в курсе их, но не слишком подчеркивайте, что вы не в курсе самой последней библиотеки. Упомянутые выше технологии достаточно хороши для многих проектов.
Но есть некоторые библиотеки, которые вам может потребоваться добавить в свой стек, потому что они специализированы для вашей области обучения.
В моем случае, чтобы изучить нейронные сети Graph и их применение в управлении цепочкой поставок, кажется, что все эти пакеты подходят. Тем не менее, в Pytorch есть более специализированные пакеты, такие как геометрическая библиотека Pytorch, которые ускорили бы мою разработку графических нейронных сетей.
Итак, мой стек будет выглядеть так:
Python + Pandas + Pytorch + Pytorch geometric + Git + Colab
Я знаю, что этот стек хорош для моего варианта использования, поскольку я изучал, как люди развиваются в этом конкретном подполе, и это то, что они используют.
Шаг 1. Изучите один проект, похожий на ваш конечный результат
Теперь, когда вы точно знаете, что хотите делать, и имеете приблизительное представление о том, как вы будете это делать, пришло время уточнить детали.
Лучший способ - это понаблюдать за работой настоящего эксперта. Вы можете рассматривать это как асинхронное обучение.

Возможность видеть конечный результат того, где вы хотите быть в действии, даст вам больше контекста для обоснования вашего обучения, чем любая теория.
Поэтому для этого лучше всего зайти на GitHub или Kaggle и проверить общедоступные проекты. Просмотрите несколько из них, пока не найдете тот, который вам нравится.
Это может быть полноценная библиотека, простой анализ или готовый к производству ИИ. Как бы то ни было, найдите несколько из них, а затем выберите один проект, который вас интересует больше всего.
Когда у вас есть этот проект, потратьте некоторое время на ознакомление с документацией, структурой кодовой базы и кодом. Скорее всего, вы заблудитесь. Особенно, если вы плохо разбираетесь в коде. Но это положительное ощущение, когда узнаешь что-то новое!
Сделайте несколько заметок о повторяющихся шаблонах, которые вы видите, интересных моментах, которые вы понимаете, или темах, которые вы действительно не понимаете. Добавьте этот проект в закладки и вернитесь к нему, когда продвинетесь по пути обучения.
Хорошее место для начала поиска - это список на GitHub. Однако простой поиск на Kaggle или GitHub ключевых слов, которые связаны с вашими интересами с помощью машинного обучения, сделает свое дело.
Для моего конкретного учебного плана хороший простой проект - это проект Томаса Кипфа. Это достаточно просто, чтобы я мог пройти по нему и понять, что происходит в каждом разделе, и в то же время изучить основы структуры.
Шаг 2. Изучите язык программирования
Теперь, когда у вас есть очень четкое представление о том, куда вам нужно идти и что вам нужно изучить, пора разобраться в коде.
Код, скорее всего, будет основан на Python, но в зависимости от того, что вы хотите изучить и какой проект вы добавили в закладки, вы можете попасть в Julia, C ++, Java или другие.
Какой бы язык это ни был, вам следует потратить некоторое время на изучение основ, чтобы понять, как составлять сценарии.

Вам не нужно на 100% понимать, как работает язык. Каждый раз, пройдя эту учебную программу, потратьте немного времени на совершенствование своих знаний на выбранном вами языке программирования, чтобы обучение было итеративным.
В моем случае для моего учебного плана курс freeCodeCamp подойдет.
Шаг 3. Изучите библиотеки сверху вниз
Одна вещь, которую я часто вижу в учебных программах по машинному обучению, - это то, что они начинают реализовывать некоторые алгоритмы с нуля после изучения основ машинного обучения.
Хотя я считаю, что это отличный проект, которым можно заняться самостоятельно, я не думаю, что это должно быть основным направлением на раннем этапе вашего пути к освоению машинному обучению.
Основная причина в том, что почти никто не реализует алгоритмы с нуля, за исключением людей, создающих пакеты, которые используют разработчики. Даже в этом случае они часто полагаются на другие пакеты, созданные специалистами по линейной алгебре, чтобы выполнять большую часть работы низкого уровня.
Все это говорит о том, что, хотя четкое понимание того, как все работает под капотом, является чистым позитивом, но я не думаю, что это должно быть ранней целью.
Что я настоятельно рекомендую на данном этапе, так это изучить библиотеку самого высокого уровня на выбранном вами языке программирования, которая приведет вас к конечным результатам. Узнайте, как использовать этот пакет сверхвысокого уровня достаточно, чтобы сделать что-то, что работает.
Вам определенно будет не хватать понимания того, почему что-то работает или нет на данный момент, но это не имеет большого значения.
Важно иметь возможность работать с инструментами, которые эксперты фактически используют изо дня в день. Как только вы поняли, что делает библиотека высокого уровня, вам следует перейти к библиотеке чуть более низкого уровня.
Однако убедитесь, что вы не слишком углубляетесь в изучение библиотеки (если вы находитесь на уровне LAPACK, читая о Фортране, вы зашли слишком далеко !!).
Для моего проекта основная библиотека, которую мне нужно изучить, - это Pytorch или его более высокая обертка, поэтому практический курс fast.ai поможет.
Шаг 4. Сделайте один проект, которым вы увлечены, максимум за один месяц
Теперь наступает фактическая часть, где произойдет наибольшее обучение. На этом этапе у вас должны быть минимальные знания, чтобы склеить проект, который имеет минимальную полезность.
Просто примечание: если вы чувствуете себя абсолютно уверенно, приступая к проекту, который планируете, значит, вы недостаточно быстро прошли шаги с 0 по 3.
Подумайте о том, что вас интересует, что вы действительно хотели бы создать и развить. Однако не сходите с ума по проекту, так как на его выполнение может уйти от 1 недели до 1 месяца.
Поместите эту дату в свой календарь с уведомлением. Наличие ограниченного по времени проекта является одновременно мотивирующим и достаточно напряженным, чтобы вы его выполнили.
Идея здесь состоит в том, чтобы приложить достаточно усилий для небольшого проекта, чтобы понять, в чем заключаются ваши основные пробелы в знаниях, и испытать то, что испытывает настоящий разработчик машинного обучения.
Пользуясь свободной формой, не прибегая к курсу или книге, вы сможете выполнять фактические части проекта машинного обучения, которые являются сложными:
- Планируйте, масштабируйте и отслеживайте прогресс вашего проекта машинного обучения
- Прочтите онлайн-документацию о библиотеках
- Прочтите StackOverflow, потоки GitHub, сообщение в блоге случайного инженера и загадочный справочный форум об этой ошибке 👺.
- Постройте свой проект неоптимальным образом и со временем улучшайте его.
- Отладка проблем с переобучением, недостаточным подбором и обобщением.
Чтобы выбрать интересующий вас проект, я предлагаю выполнить эти три небольших упражнения:
- Глубоко подумайте о том, что вас сейчас интересует
- Посмотрите список проектных идей
- Взгляните на открытые наборы данных
Комбинируя эти три вещи, вы сможете сформировать больше контекста о том, что возможно. Вы также будете смешивать и сочетать свои интересы, чтобы сделать что-то действительно своим.
Этот список на Github должен стать отличным местом для вдохновения при создании мини-проекта. Затем вы можете объединить это с поисковой системой Google Dataset Search, чтобы найти данные, соответствующие вашему проекту.
⚠️ Не стоит недооценивать важность данных. ⚠️
Даже если у вас есть очень хорошие идеи, отсутствие данных серьезно помешает вашему прогрессу.
Для моих интересов я нашел этот аккуратный набор данных о глобальной цепочке поставок горнодобывающей компании, в котором достаточно данных, чтобы что-то из них сделать. Мой проект будет посвящен моделированию данных в виде графика и использованию графических нейронных сетей для определения продажных цен на экскаватор, что является центральной темой этого набора данных.
Шаг 5. Определите один пробел в своих знаниях и узнайте о нем
На этом этапе вы потратили некоторое время на разработку своего проекта и действительно впечатлены тем, как далеко вы продвинулись в этом. Вероятно, это далеко не то, что вы имели в виду, и вы столкнулись с бесчисленным множеством проблем на своем пути.
Теперь вы понимаете, как мало вы на самом деле знаете и что есть некоторая часть ваших знаний, которую вам действительно нужно исправить.

Отлично! Составьте список всех пробелов, которые вы видели на своем пути, и расположите их в порядке предполагаемого приоритета. Это может быть сложно для вас, так как на этом этапе все будет выглядеть очень важным. Но выполнение упражнения по принятию осознанного решения о том, что изучать дальше, почти так же ценно, как и само обучение.
А теперь самое странное: удалите все из своего списка и выучите только самые важные знания.
Когда я говорю «удалите», я имею в виду именно это. Удалите все, кроме первого. Когда вы сделаете еще один проход в этом цикле, ваша оценка того, что изучать дальше, будет в основном неверной, и вам будет не хватать других более важных знаний, о которых вы не знали.
Теперь, когда вам осталось изучить только один предмет, дайте себе от 1 дня до 1 недели, чтобы изучить эту конкретную тему. Это может показаться очень коротким сроком, но то, что вы действительно хотите здесь, - это получить достаточно глубокие знания, чтобы быть функциональными для вашего следующего раунда обучения.

На практике может случиться так, что вы достаточно глубоко погрузитесь в эту тему, чтобы заметить, как она связана с другими важными темами (такими как вероятность, статистика или даже богом забытая линейная алгебра).
Внимательно изучите эти ссылки, следуйте по ним, если хотите, и укрепите свою ментальную модель машинного обучения, чтобы сделать ее более точной.
Шаг 6: повторите шаги с 0 по 5.
Ваш первый проход по этому конвейеру, скорее всего, будет в лучшем случае так себе. Но вы узнаете гораздо больше за очень короткий период времени, чем все, что вы могли бы достичь с помощью подхода «снизу вверх».
Ценность, которую вы получите от этого метода, довольно быстро увеличивается на каждом проходе конвейера. Каждый раунд будет легче, и вы получите более четкую картину поля.
Эта методология основана на методологии бережливого производства, которую я с большим успехом научился применять в своем стартапе. Выполнение нескольких итераций по теме, для которой вы оптимизируете, - это самый быстрый способ достичь своей цели.
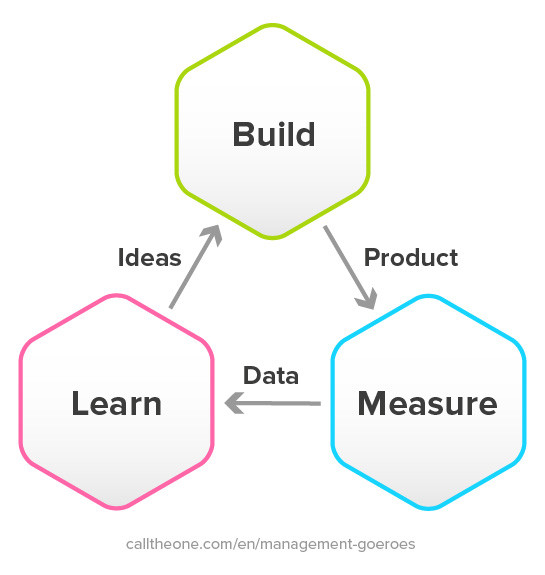
В течение года вы, возможно, сможете провести 12 проходов через этот конвейер, что означает 12 проектов машинного обучения и очень практическое понимание области.
Этот метод сделает вас очень востребованным и даст вам инструменты, необходимые для самосовершенствования.
Также, как примечание для людей, которые уже знакомы с машинным обучением, это градиентный спуск. Вы буквально делаете градиентный спуск по проблеме «освоение машинному обучению», делая небольшой шаг в плоскости затрат из-за своего незнания.
Вы даже делаете вариант градиентного спуска, который смотрит вперед в плане затрат и может замедляться (тратить больше времени на проект или концепцию обучения) или ускоряться (пропускать, если тема не так актуальна для вашего понимания). В двух словах, это градиент с ускорением Нестерова 😄 (лол извините за этот бит)!

Резюме и заключение
Таким образом, вам следует:
- Выяснить, как выглядит поле машинного обучения, и составьте его мысленную карту.
- Найти крутой проект, которым вы бы хотели заняться, и изучить его.
- Изучить необходимый язык программирования.
- Выучить достаточно библиотек, чтобы делать что-нибудь полезное.
- Сделать проект за [1 неделю, 1 месяц].
- Узнать о том, что вы считали большим пробелом в своих знаниях.
- И еще раз повторить!
Всего хорошего